1 2 3 4 5
1 0.45 0.09 0.26 0.09 0.10 2 0.04 0.41 0.31 0.13 0.10 3 0.06 0.15 0.52 0.12 0.16 4 0.04 0.14 0.25 0.36 0.20 5 0.04 0.09 0.30 0.18 0.39
Introduction
All the datasets here contain the following information:
You can read the datasets using read_from_data_file function as :
[similarity,cluster_assignments,points]=read_from_data_file(filePrefix,directory)
(see the documentation for more details. Also you can create your own datasets using write_data_file function)
(Please refer to the related paper for explanation of the terms mentioned here)
These are artificial datasets which are generated so that the stochastic matrix corresponding to the similarity matrix is block stochastic. There are five true clusters consisting of 10,20,30,20 and 20 points respectively
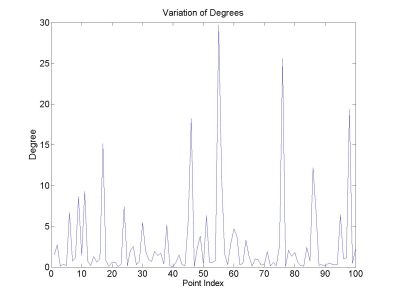
The first dataset was designed to be "hard". i.e. there is a large variation between the "degrees" from one point to another and there is reasonable amount of cross talk between clusters. Also the smallest degrees are in the smallest cluster making it easy to "lose" that cluster in noise. The cross talk and the variation of degrees is shown below.
|
The Cross talk : The numbers represent combined probability
of going from one cluster to another.
1 2 3 4 5 1 0.45 0.09 0.26 0.09 0.10 2 0.04 0.41 0.31 0.13 0.10 3 0.06 0.15 0.52 0.12 0.16 4 0.04 0.14 0.25 0.36 0.20 5 0.04 0.09 0.30 0.18 0.39
|
Another block stochastic dataset is also available. It is similar to one above except that it is less extreme and comparatively simpler to cluster.
600K_nobiasswarm1.mat, with the vector xyz containing X,Y,Z coordinates x 6 atoms in the system x number of simulation steps (about 6,000 -- 25,000). The "preprocessed" files contain the xyz data preprocessed as described in this paper (link to be added).
This is the set of optical handwritten digit recognition that is available in the NIST site.There are lots of version available with different preprocessing. In particular we used the data set and preprocessing as mentioned in http://ftp.ics.uci.edu/pub/machine-learning-databases/optdigits/optdigits.names . (This is one of the UCI Datasets :"Optical Recognition of Handwritten Digits").We further down sampled the dataset to 100 elements per digit giving a total of thousand 64 dimensional points
The 10 digit dataset is available here. A
quick look at the similarity matrix shows that the digits 0,2,4,6,7 are
well separated. So we created another dataset consisting of just these points
which is located here.